Serverless Architectures with Amazon DynamoDB and Amazon Kinesis Streams with AWS Lambda
Overview
In this tutorial, you will learn the basics of event-driven programming using Amazon DynamoDB, DynamoDB Streams, and AWS Lambda. You will walk through the process of building a real-world application using triggers that combine DynamoDB Streams and Lambda.
TOPICS COVERED
By the end of this tutorial, you will be able to:
- Create an AWS Lambda function from a blueprint
- Create an Amazon Kinesis Stream
- Use Amazon CloudWatch to monitor Kinesis event data triggering your Lambda function
- Create an Amazon DynamoDB table and insert items
- Enable the Amazon DynamoDB Streams feature
- Configure and troubleshoot Lambda functions
About the Technologies
AWS LAMBDA
Lambda is a compute service that provides resizable compute capacity in the cloud to make web-scale computing easier for developers. You can upload your code to AWS Lambda and the service can run the code on your behalf using AWS infrastructure. AWS Lambda supports multiple coding languages: Node.js, Java, or Python. After you upload your code and create a Lambda function, AWS Lambda takes care of provisioning and managing the servers that you use to run the code.
In this tutorial, you will use AWS Lambda as an event-driven compute service where AWS Lambda runs your code in response to changes to data in and SNS topic and an Amazon S3 bucket.
You can use AWS Lambda in two ways:
As an event-driven compute service where AWS Lambda runs your code in response to events, such as uploading image files as you will see in this lab.
As a compute service to run your code in response to HTTP requests using Amazon API Gateway or API calls.
Lambda passes on to you the financial benefits of Amazon’s scale. AWS Lambda executes your code only when needed and scales automatically, from a few requests per day to thousands per second. With these capabilities, you can use Lambda to easily build data processing triggers for AWS services like Amazon S3 and Amazon DynamoDB, process streaming data stored in Amazon Kinesis, or create your own back end that operates at AWS scale, performance, and security.
This lab guide explains basic concepts of AWS in a step by step fashion. However, it can only give a brief overview of Lambda concepts. For further information, see the official Amazon Web Services Documentation for Lambda at https://aws.amazon.com/documentation/lambda/. For pricing details, see https://aws.amazon.com/lambda/pricing/.
LAMBDA BLUEPRINTS
Blueprints are sample configurations of event sources and Lambda functions that do minimal processing for you. Most blueprints process events from specific event sources, such as Amazon S3 or DynamoDB. For example, if you select an s3-get-object blueprint, it provides sample code that processes an object-created event published by Amazon S3 that Lambda receives as parameter.
When you create a new AWS Lambda function, you can use a blueprint that best aligns with your scenario. You can then customize the blueprint as needed. You do not have to use a blueprint (you can author a Lambda function and configure an event source separately).
AMAZON DYNAMODB
Amazon DynamoDB is a fast and flexible NoSQL database service for all applications that need consistent, single-digit millisecond latency at any scale. It is a fully managed database and supports both document and key-value data models. Its flexible data model and reliable performance make it a great fit for mobile, web, gaming, ad-tech, IoT, and many other applications. For further information, see the official Amazon Web Services Documentation for DynamoDB at https://aws.amazon.com/documentation/dynamodb/.
Part 1: Event-Driven Programming with Amazon Kinesis and AWS Lambda
In the first part of this lab, you will learn event-driven programming with Kinesis and Lambda.
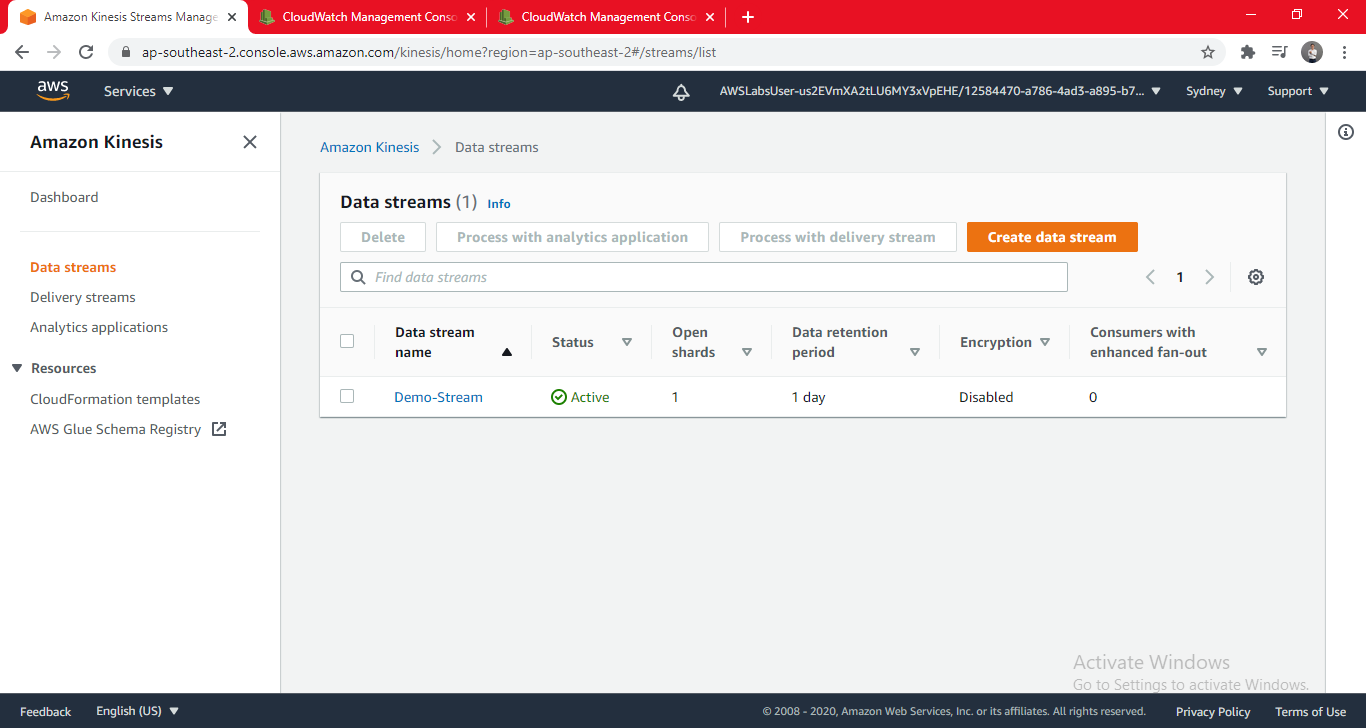
Task 1: Create an Amazon Kinesis Stream
In this task, you will create an Amazon Kinesis stream.
- In the AWS Management Console, click Services then click Kinesis.
- Under the How it works section, click Create data stream then configure:
- Kinesis stream name:
- Demo-Stream
- Number of shards: 1 (Each shard supports a pre-defined capacity, as shown in the Total stream capacity section. This lab only requires one shard, but applications requiring more capacity can simply request more shards.)
- Click Create Kinesis stream
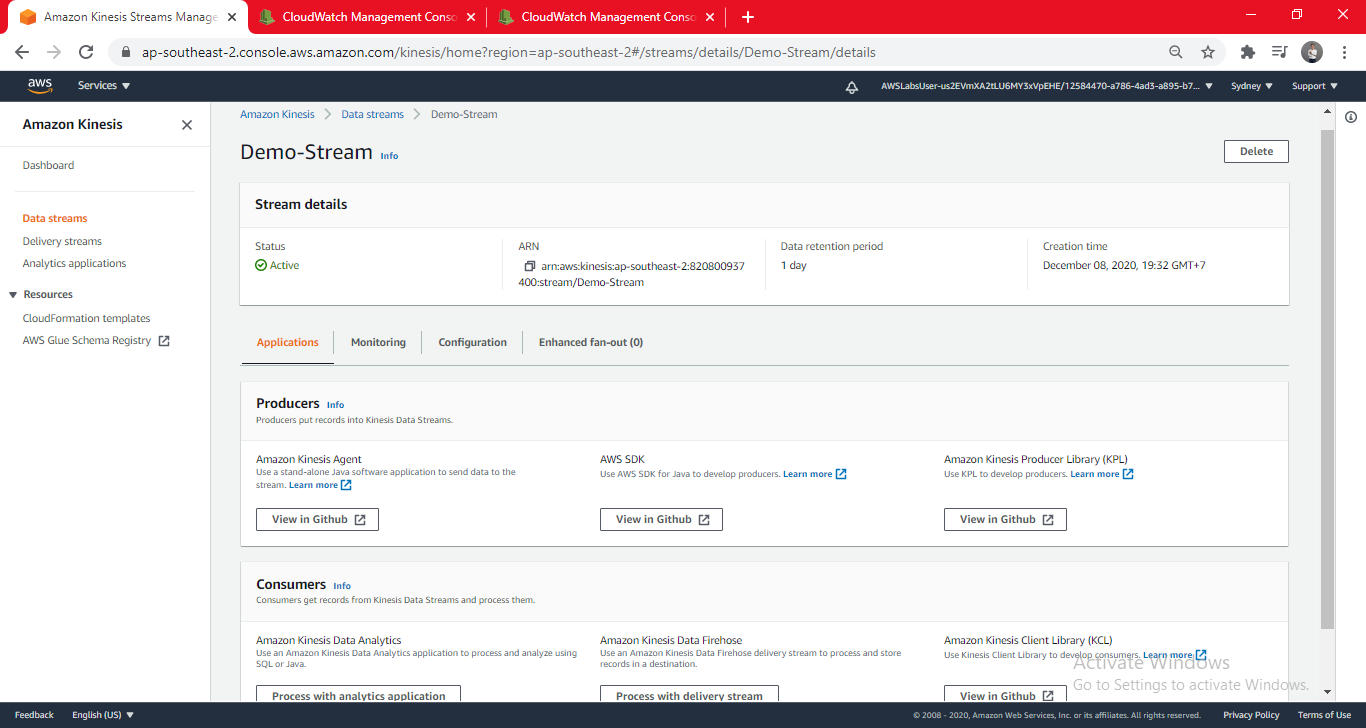
- On the Services menu, click Lambda.
- Click Create function (You will start by selecting a Lambda blueprint. Blueprints are pre-built for you and can be customized to suit your specific needs)
- Select Use a blueprint, then:
- Click the Blueprints search box
- Search for: kinesis-process-record-python
- Select kinesis-process-record-python
- Click Configure
- In the Basic information section, configure:
- Function name: ProcessKinesisRecords
- Execution role: Use an existing role
- Existing role: lambda_basic_execution
- In the Kinesis trigger section, configure:
- Kinesis stream: Demo-Stream
- Check Enable trigger (This will configure the Lambda function so that it is triggered whenever data comes into the Kinesis stream you created earlier.)
- Scroll down and examine the Lambda blueprint displayed in the Lambda function code section. It does the following:
- Loop through each of the records received
- Decode the data, which is encoded in Base 64
- Print the data to the debug log
- At the bottom of the screen, click Create function (This function will now trigger whenever data is sent to the stream.)
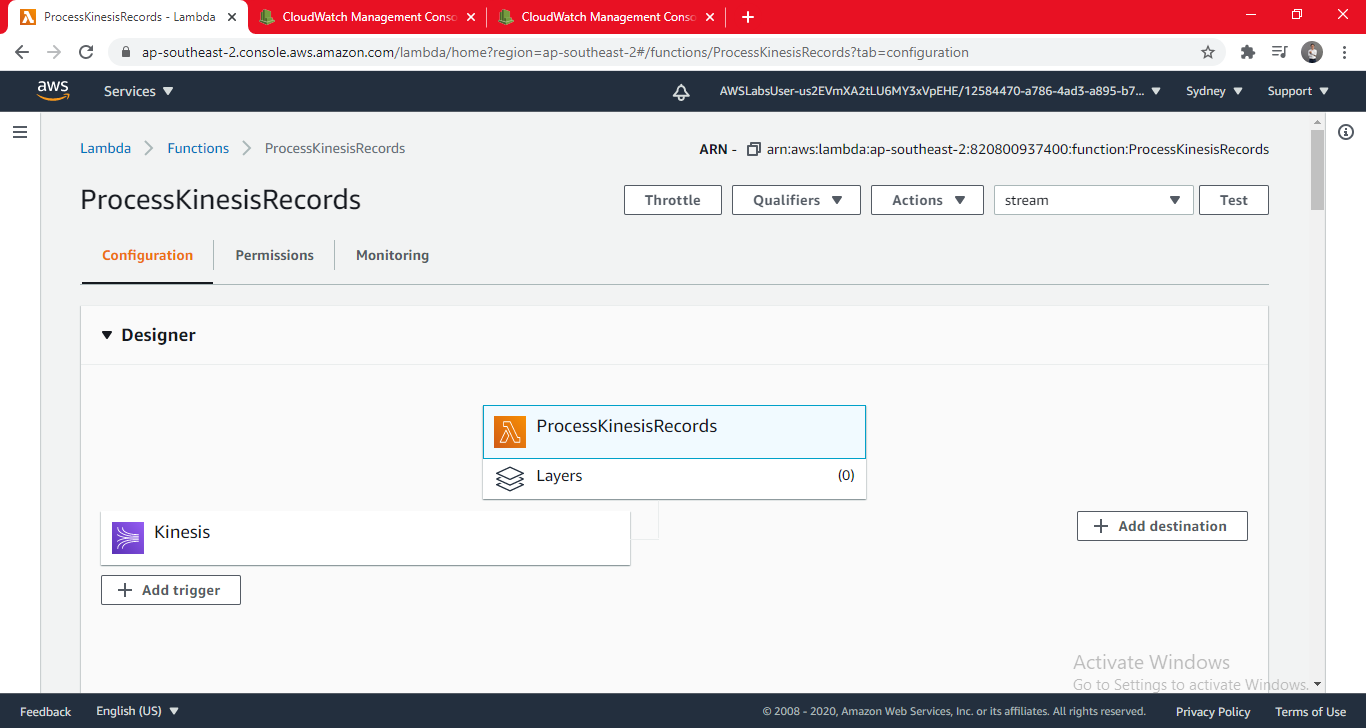
- Click Test (An event template for Kinesis will be automatically selected. The event contains a simulated message arriving via Kinesis.)
- For Event name, enter: stream
- Click Create
- Click Test (You should see the message: Execution result: succeeded)
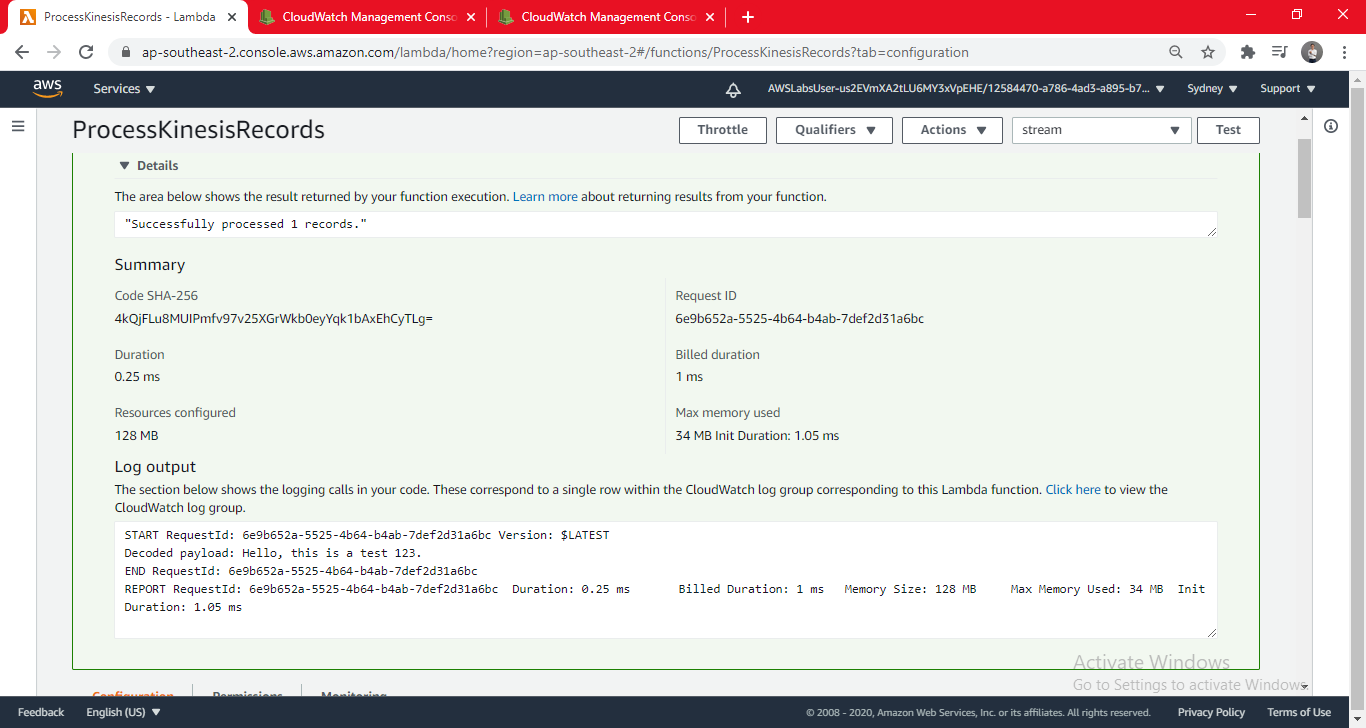
- Expand Details to view the output of the Lambda function. You will be shown information about the Lambda execution:
- Execution duration
- Resources consumed
- Maximum memory used
- Log output
- Click the test button another three times, waiting a few seconds between each test. (This will generate test data for Amazon CloudWatch.)
- Click the Monitoring tab. (You will be presented with CloudWatch metrics for your Lambda function. Metrics should be available for Invocations and Duration. If the metrics do not appear, wait a minute and then click refresh.)
- On the Services menu, click DynamoDB.
- Click Create table and configure:
- Table name: GameScoreRecords
- Primary key: RecordID
- Primary key type: Number
- Click Create
- You will now create another table for linking scores to users.
- Click Create table and configure:
- Table name: GameScoresByUser
- Primary key: Username
- Primary key type: String
- Click Create
- You can now activate DynamoDB Streams on the first table. This will generate streaming data whenever there is any change to the table (insert, update, delete).
- Click the first table you created, GameScoreRecords.
- On the Overview tab, click Manage DynamoDB Stream then configure:
- View type: New image-the entire item, as it appears after it was modified
- Click Enable (Any record sent to this table will now send a message via DyanmoDB streams, which can trigger a Lambda function.)
- On the Services menu, click Lambda.
- Click Create function
- You will be providing the code to run, so click on Author from scratch.
- Configure the following:
- Function name: AggregateScoresByUser
- Runtime: Node.js 12.x
- Expand Change default execution role
- Select Execution role: Use an existing role
- Expand Existing role: lambda_basic_execution_dynamodb
- Click Create function
- Scroll down to the Function code section, then:
- Delete all of the code in the index.js editor
- Copy and paste this code into the index.js editor: CLICK HERE TO VIEW CODE
- Examine the code. It does the following:
- Loop through each incoming record
- Create (ADD) an item in the GameScoresByUser table with the incoming score
- Wait until all updates have been processed
- Click Deploy. (You will now configure the function to execute when a value is added to the DynamoDB table.
- Scroll up to the Designer section.
- Click Add trigger then configure:
- In the Trigger configuration section, configure the following:
- Select a trigger: click DynamoDB.
- DynamoDB table: GameScoreRecords
- Click Add (The function will now be triggered when a new game score is added to the DynamoDB table. You can now test the function with a record that simulates an update of the database.)
- Click Test
- For Event name, enter: score
- Delete the existing test code (with key3, etc).
- Copy and paste this record into the test event window: Examine the test record. It is simulating an incoming record from the GameScoreRecords table. CLICK HERE TO VIEW CODE
- At the bottom of the page, click Create
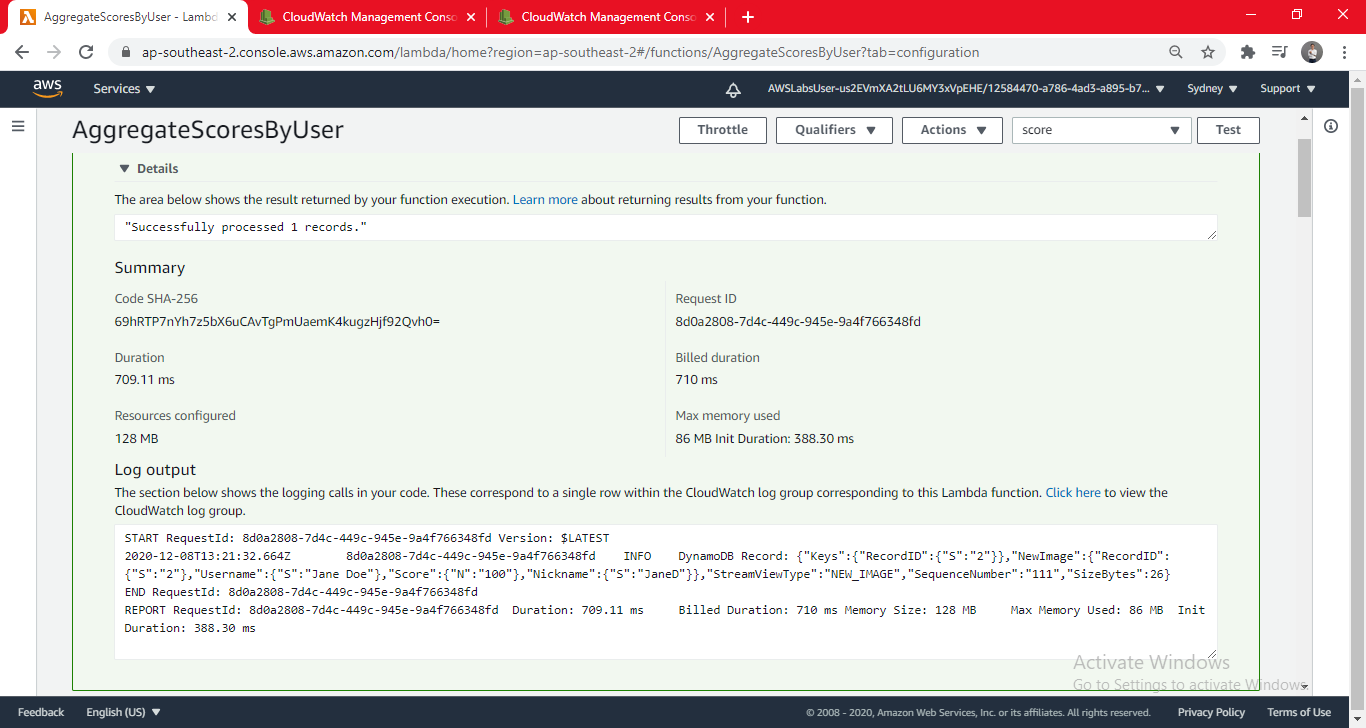
- Click Test (Your Lambda function will be invoked. The heading (towards the top of the page) should say Execution result: succeeded.)
- Expand Details to view the output of the Lambda function. You should see: Successfully processed 1 records.
- VERIFY IN DYNAMODB - You will now verify that the data was updated in DynamoDB.
- On the Services menu, click DynamoDB.
- In the left navigation pane, click Tables.
- Select GameScoreByUser.
- Click the Items tab. (This table was previously empty (you created it yourself), but you should now see an entry for Jane Doe.)
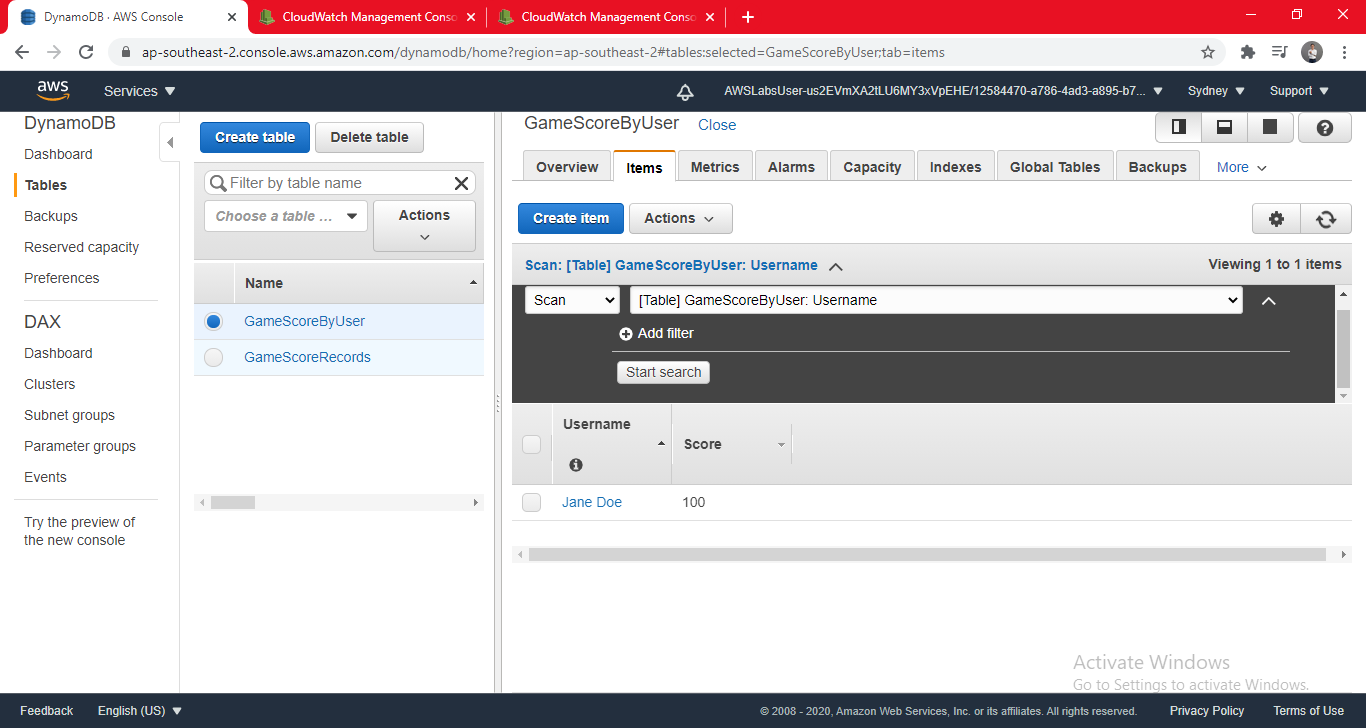
- TRIGGER THE UPDATE - You can perform more tests by inserting values in the Scores table, and confirming that the Lambda updates the User table.
- Select the GameScoreRecords table.
- Click Create item then for RecordID, enter any number.
- Enter a user name:
- Click > Append > String
- For FIELD, enter: Username
- For VALUE, enter a person’s name
- You will now add a score:
- Clicking > Append > Number
- For FIELD, enter: Score
- For VALUE, enter a random score
- Click Save - Your new item will be displayed. It should have also triggered the Lambda function, resulting in a new entry in the other table.
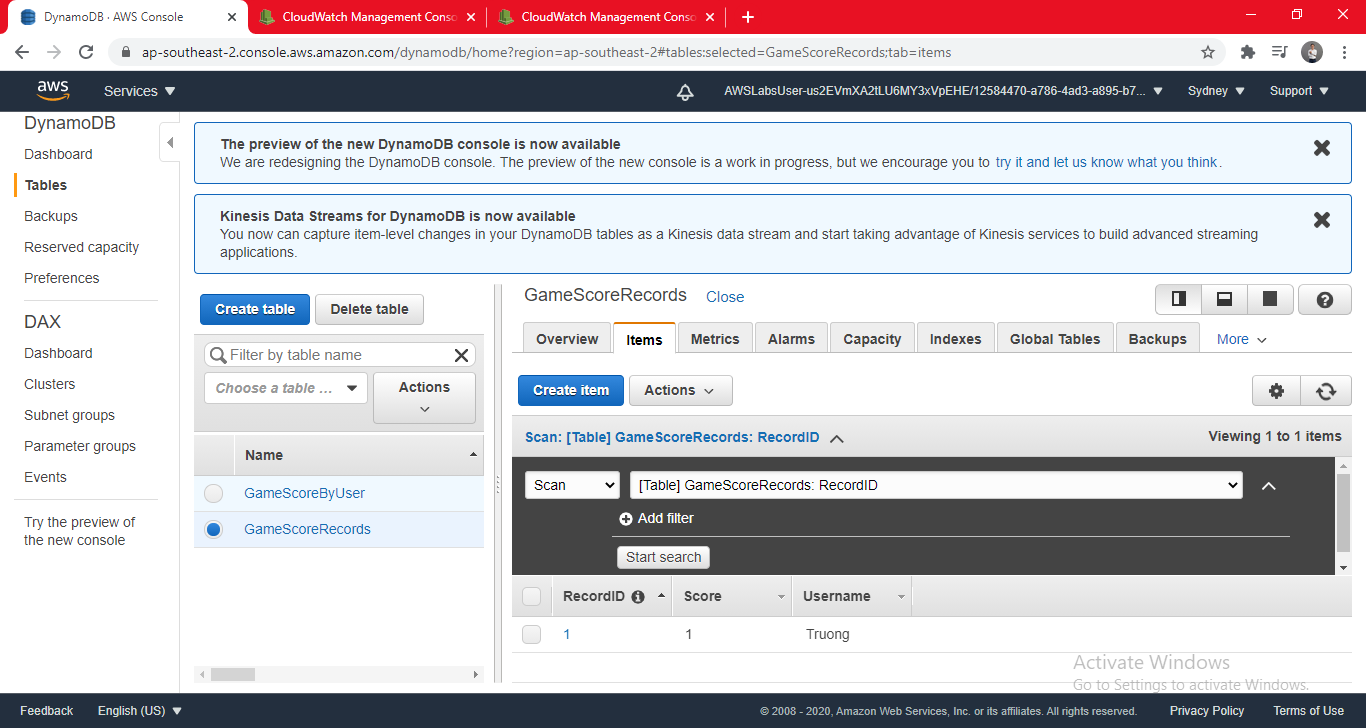
- Click the GameScoresByUser table. You should see that the new data you entered has been copied to the User table. Feel free to repeat the test by adding more items in the GameScoreRecords table.
Comments